
Introduction to Time Series Forecasting
Time series forecasting is an essential aspect of data analysis, allowing businesses and researchers to predict future values based on historical data. Imagine being able to forecast stock prices, weather patterns, or even sales trends with a high degree of accuracy. Sounds intriguing, right? That’s where the sklearn dta set timeseries comes into play.
With its robust tools and algorithms, Scikit-learn has become a go-to resource for machine learning practitioners looking to unravel the mysteries hidden within temporal datasets. Whether you are a seasoned data scientist or just starting out on your journey in machine learning, understanding how to leverage this powerful library can set you apart in today’s competitive landscape.
This blog post will guide you through key concepts related to time series forecasting using the sklearn dta set timeseries. From grasping the foundational elements of time series analysis to exploring common machine learning models used for predictions, you’ll discover actionable insights that can elevate your projects. Get ready to dive deep into the world of predictive analytics!
Understanding the Sklearn Dataset
The sklearn dta set timeseries is a rich resource for those looking to delve into machine learning applications. It provides various datasets designed specifically for time series analysis.
One of the key features of these datasets is their structured format, which makes it easier to handle sequential data. This structure allows users to explore trends and patterns over specific intervals.
Moreover, the datasets often come with built-in functions that simplify preprocessing tasks. You can quickly access essential statistical information, enabling efficient model training.
Understanding this dataset also means familiarizing yourself with its unique attributes. Features like timestamps and lagged values play critical roles in forecasting accuracy.
For practitioners, leveraging this dataset can enhance predictive modeling capabilities significantly. With proper understanding and application, you can unlock valuable insights from historical data trends.
Data Preprocessing for Time Series Analysis
Data preprocessing is a crucial step in time series analysis. It ensures that your dataset is clean and ready for modeling.
Start by handling missing values. Time series data can often have gaps due to various reasons, like sensor malfunctions or human errors. Interpolating these gaps can provide a more complete picture.
Next, consider transforming the data. Normalization or standardization helps scale features to a uniform range, which is especially important for algorithms sensitive to feature magnitude.
Another vital aspect is time indexing. Make sure your timestamps are properly formatted and sorted chronologically. This organization aids in capturing trends accurately over time.
You may want to create additional features from existing ones—like lagged variables or rolling averages—to enrich your dataset further. These enhancements enable models to glean insights that raw data might obscure.
Common Machine Learning Models used for Time Series Forecasting
When it comes to time series forecasting, several machine learning models shine. Each model has its unique strengths and weaknesses.
ARIMA (AutoRegressive Integrated Moving Average) is a classic choice. It excels in capturing trends and seasonality patterns in data. However, it requires stationary data for optimal results.
Another popular option is the Seasonal Decomposition of Time Series (STL). This method breaks down the components into trend, seasonal, and residual parts. It’s particularly beneficial when dealing with complex datasets exhibiting multiple seasonalities.
For those seeking a more modern approach, Long Short-Term Memory networks (LSTM) are worth considering. These deep learning models can handle long dependencies in data sequences effectively.
Random Forests also find their place in time series forecasting. With ensemble methods like these, you can manage nonlinear relationships well while avoiding overfitting issues common with single decision trees.
Each of these models offers distinct advantages that cater to different types of time series data.
How to Evaluate Model Performance
Evaluating model performance is crucial in time series forecasting. It helps determine how well your machine learning model predicts future values.
One common metric is Mean Absolute Error (MAE). This measures the average magnitude of errors in a set of predictions, without considering their direction. Lower MAE indicates better predictive accuracy.
Another important measure is Root Mean Squared Error (RMSE). RMSE gives higher weight to larger errors, making it sensitive and useful for identifying significant discrepancies between predicted and actual values.
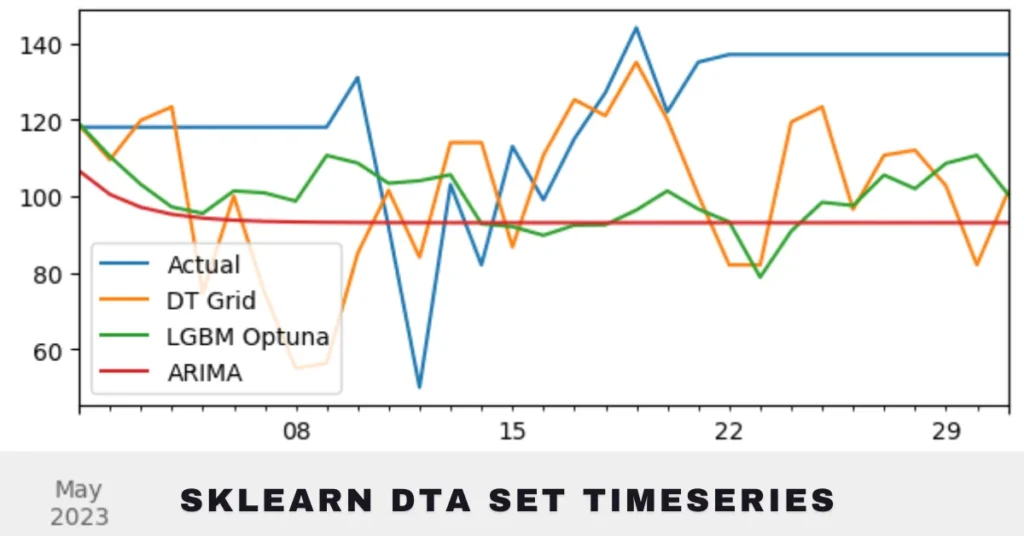
Additionally, using visualizations like prediction plots can provide insights into where models succeed or fail. These plots show actual versus predicted values over time, allowing you to spot trends and anomalies easily.
Cross-validation techniques also play a role here. By training multiple models on different segments of data, you can gauge stability and reliability across various time frames.
Case Study: Predicting Stock Prices using the Sklearn Dataset
Predicting stock prices is a complex but fascinating application of machine learning. Using the Sklearn dataset, we can explore historical price data to build robust forecasting models.
We start by gathering daily stock prices over several years. This forms our time series data, which includes opening and closing prices, volume traded, and other relevant indicators.
Data preprocessing is crucial here; it involves handling missing values and normalizing the dataset for better model performance. We might also consider adding features like moving averages or volatility indicators to enrich our analysis.
Once prepared, we can apply various algorithms such as linear regression or LSTM networks specifically suited for sequential data. Each model offers unique insights into trends and patterns that could influence future price movements.
The results can be visually represented through graphs showing predicted versus actual prices over time, allowing us to assess the effectiveness of our approach in real-world scenarios.
Challenges and Limitations of Time Series Forecasting with Sklearn Dataset
Time series forecasting using the Sklearn dataset comes with its own set of challenges. One major hurdle is dealing with non-stationarity in data. Time-dependent trends and seasonal patterns can skew results, making it hard for models to predict accurately.
Another limitation is the scarcity of labeled data for training. Many time series datasets lack sufficient historical records, which are crucial for building robust predictive models. This often leads to overfitting or underfitting issues during model training.
Additionally, many traditional machine learning algorithms don’t inherently consider temporal dependencies. As a result, they may overlook significant shifts that occur over time. Choosing features wisely becomes essential but also tricky.
Computational resources can be a constraint when working with large datasets typical in time series analysis. Models may require extensive processing power and memory which can hinder accessibility for smaller projects or individual researchers.
Future Developments and Applications of Time Series Forecasting with Sklearn Dataset
The future of time series forecasting with the Sklearn dataset holds immense promise. As machine learning techniques evolve, we can expect more sophisticated models that enhance prediction accuracy.
New algorithms are emerging, allowing for better handling of seasonal variations and trends. Advanced neural network architectures like LSTM (Long Short-Term Memory) could seamlessly integrate into existing frameworks.
Moreover, integrating real-time data streams will transform how businesses approach forecasting. This capability enables quicker adjustments based on sudden market changes or unforeseen events.
In practical applications, sectors from finance to healthcare will benefit significantly. Predictive analytics could lead to smarter stock trading strategies or improved patient outcome forecasts.
Additionally, automated model selection processes may simplify workflows for analysts and developers alike. Improved user interfaces in tools like Sklearn could make these advanced capabilities accessible to non-experts as well.
Conclusion
Time series forecasting is a powerful tool for predicting future values based on past observations. By leveraging the Sklearn dataset, one can effectively apply machine learning techniques to tackle this complex task. The versatility of Sklearn allows data scientists and analysts to preprocess their data efficiently while experimenting with various models.
Evaluating model performance is crucial in ensuring reliable predictions. With metrics like Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE), practitioners can gain insights into how well their models perform over time.
The case study on stock price prediction illustrates the practical application of these concepts. While challenges exist, such as handling seasonality or trend changes, advancements in technology continue to pave the way for more robust solutions.
As we move forward, integrating Sklearn’s capabilities with newer methodologies will further enhance our ability to forecast time series data accurately. This evolving landscape promises exciting opportunities across various industries—from finance to weather forecasting—where informed decisions are paramount.
With ongoing developments in machine learning algorithms and tools, enthusiasts and professionals alike have much to anticipate in the realm of time series analysis using sklearn datasets. Embracing these innovations could lead us toward unprecedented accuracy and efficiency in our predictive endeavors.
FAQs
What is “sklearn dataset time series”?
sklearn dta set timeseries refers to datasets provided by the Scikit-learn library, specifically designed for time series analysis and machine learning forecasting.
How do I preprocess time series data for machine learning?
Preprocessing involves handling missing values, normalizing or standardizing data, and creating additional features like lagged variables or moving averages to improve model accuracy.
What are some common machine learning models for time series forecasting?
Popular models include ARIMA, Seasonal Decomposition of Time Series (STL), LSTM networks, and Random Forests, each catering to different types of time series data.
How do I evaluate time series forecasting models?
Model performance can be evaluated using metrics like Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and visualizations like prediction plots.
What challenges arise when forecasting time series with sklearn datasets?
Challenges include non-stationary data, lack of labeled training data, temporal dependencies, and computational resource constraints when working with large datasets.





